Guidance and resources
Improving access and widening participation interventions in higher education are designed to produce a range of outcomes, and effective evaluation of such activities has become increasingly important.
Many interventions are not compatible with conventional forms of causal inference, such as systematic review, randomised controlled trial and quasi-experimental design, due to their complex nature, resource issues, emergent or developmental features, or small scale.
These resources focus on alternative approaches to causal inference, known as theory-based evaluation methods.
Impact evaluation is important but can be challenging. TASO promotes the use of rigorous experimental and quasi-experimental impact evaluation methodologies as these are often the best way to determine causal inference. However, sometimes these types of impact evaluation raise challenges:
An alternative group of impact evaluation methodologies, sometimes referred to as theory-based methodologies, can address some of these challenges:
- They only need a small number of cases or even a single case. The case is understood to be a complex entity in which multiple causes interact. Cases could be individual students or groups of people, such as a class or a school. This can be helpful when a programme or intervention is designed for a small cohort or is being piloted with a small cohort.
- They can ‘unpick’ relationships between causal factors that act together to produce outcomes. In theory-based evaluation methodologies , multiple causes are recognised and the focus of the impact evaluation switches from simple attribution to understanding the contribution of an intervention to a particular outcome. This can be helpful when services are implemented within complex systems.
- They can work with emergent interventions where experimentation and adaptation are ongoing. Generally, experiments and quasi-experiments require a programme or intervention to be fixed before an impact evaluation can be performed. Theory-based methods can, in some instances, be deployed in interventions that are still changing and developing.
- They can sometimes be applied retrospectively. Most experiments and some quasi-experiments need to be implemented at the start of the programme or intervention. Some theory-based evaluation methodologies can be used retrospectively on programmes or interventions that have finished.
Webinar
Watch our webinar which provides an introduction to the guidance.
Further guidance
What is evaluation?
What is evaluation?
Evaluation is a broad concept that can be difficult to distinguish both from other types of research and related practices such as monitoring and performance management. There is no single, widely accepted definition of evaluation. The Magenta Book, the UK government’s guidance on evaluation, defines evaluation as:
“A systematic assessment of the design, implementation and outcomes of an intervention. It involves understanding how an intervention is being, or has been, implemented and what effects it has, for whom and why. It identifies what can be improved and estimates its overall impacts and cost-effectiveness.”
The Magenta Book
Definitions of evaluation often emphasise that evaluations make judgements while also maintaining a level of objectivity or impartiality. This helps distinguish evaluation from other types of research. So, for example, Mark et al. (2006), in the introduction to the Sage Handbook of Evaluation, define evaluation as:
“A social and politicized practice that nonetheless aspires to some position of impartiality or fairness, so that evaluation can contribute meaningfully to the well-being of people in that specific context and beyond.”
Sage Handbook of Evaluation
Some definitions of evaluation also emphasise that it uses research methods, and this is helpful in distinguishing evaluation from similar practices such as monitoring and performance management. For example, Rossi and colleagues in Evaluation: A Systematic Approach define evaluation as:
“The application of social research methods to systematically investigate the effectiveness of social intervention programs in ways that are adapted to their political and organizational environments and are designed to inform social action to improve social conditions.”
Evaluation: A Systematic Approach
Fox and Morris (2020) in the Blackwell Encyclopaedia of Sociology combine these different elements and define evaluation as:
“The application of research methods in order to make judgments about policies, programs, or interventions with the aim of either determining or improving their effectiveness, and/or informing decisions about their future.”
Blackwell Encyclopaedia of Sociology
Evaluation takes various forms, and distinctions can be made according to the aim of the evaluation. Impact evaluations are concerned with establishing the existence or otherwise of a causal connection between the programme or intervention being evaluated and its outcomes. The most common type of impact evaluation involves comparing the average outcome for an intervention group and a control group. Sometimes, cases (for example students) are assigned randomly to intervention and control groups: this is known as a randomised controlled trial. This guide is about a different approach to impact evaluation that involves only one or a small number of cases and does not involve a control group. Causality can still be inferred but cannot generally be quantified.
Why is impact evaluation important?
- Impact evaluations help decide whether a programme or scheme should be adopted, continued or modified for improvement. They help institutions to understand what works and to make better decisions on what to invest in and when to disinvest.
- As outlined by the Office for Students (OfS), all evaluations funded or co-funded by access and participation plans should contain some element of impact evaluation. This is important in demonstrating that initiatives have the desired impact on student outcomes
- Impact evaluation is particularly important when designing and implementing an innovative programme or service to ensure that it has the intended effect and does not lead to unintended negative outcomes.
What is causation?
What is causation?
Causal inference is key to impact evaluation. An impact evaluation should allow the evaluator to judge whether the intervention being evaluated caused the outcome being measured. Causation differs from correlation. If you are unsure of this difference, please watch this TASO causality webinar.
Different approaches to impact evaluation can invoke different understandings of causal inference. There is a fundamental distinction between the two types of question that social scientists ask when using the tools and techniques of social science in evaluation. First, they may ask the question: what are the effects of a causal factor (i.e. an intervention or treatment)? Second, and in contrast, they may ask the question: what are the causal factors that give rise to an effect? These questions are what Dawid (2007) calls ‘effects of causes’ and ‘causes of effects’ type questions (Figure 1).
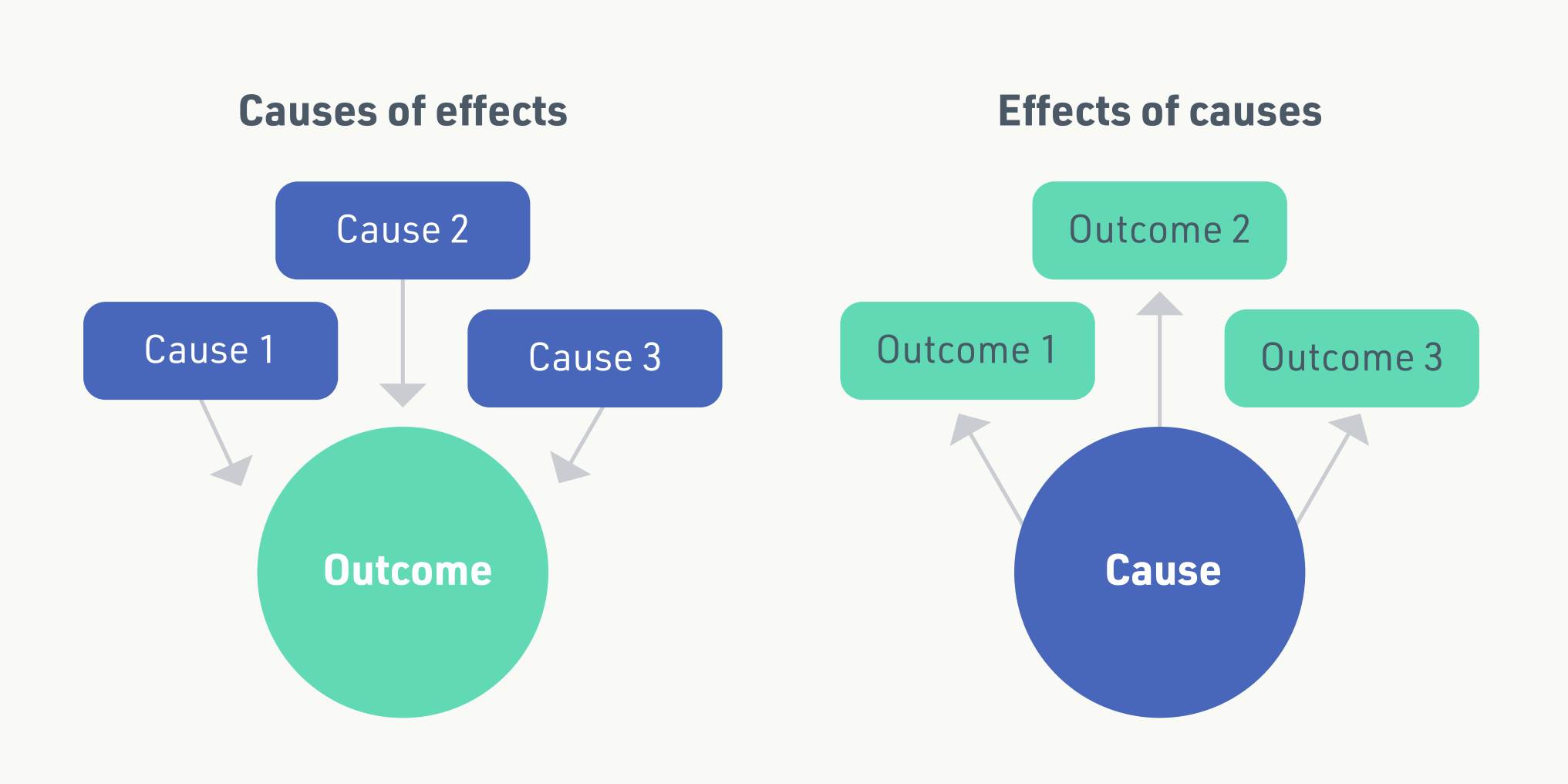
A classic ‘effects of causes’ approach to impact evaluation would be a randomised controlled trial (RCT) design. This is what the OfS standards of evidence refer to as a ‘Type 3’ evaluation. Randomised experiments are used widely in evaluation and are designed to establish whether there is causality between an intervention and the outcomes. In its simplest form, a randomised experiment involves the random allocation of subjects to intervention and control groups.
Subsequent differences in the average outcomes observed in these two groups are understood to provide an unbiased estimate of the causal effect of the intervention. The design draws on the tradition of controlled experiments in medicine, psychology and agriculture but has been developed to evaluate social programs. Where randomised experiments are not possible, several ‘quasi-experimental’ designs have been developed that replicate the experimental logic (Shadish, Cook and Campbell, 2002).
In a ‘causes of effects’ approach to impact evaluation, the intervention is understood as producing effects through mechanisms which, as Cartwright and Hardie (2012) describe, act as just one ingredient in a ‘causal cake’. The various relevant ingredients need to be identified, defined and explored before the causal question can be fully addressed, and causation or otherwise inferred. Here the emphasis is on an explanation of the effects or outcomes that are altered through the triggering of causal mechanisms. Specifically, the evaluation is concerned with the role of the intervention in these processes. In other words, causes work together in causal packages to produce effects (Cartwright & Hardie, 2012). The theory-based approaches to evaluation described here are based on the ‘causes of effects’ approach to impact evaluation.
What is theory-based evaluation?
What is theory-based evaluation?
Theory-based evaluations can be a good option when there are not enough cases to construct a ‘traditional’ counterfactual impact evaluation. – Instead, theory-based evaluation methods use a theory of change to explain how the intervention might create an impact and, – together with alternative causal hypotheses, test the theory in the data collection process.
Theory-based evaluation designs should be considered when one or more of the following are true:
- There is one case or a small number of cases. A case could be a person, an organisation, a school or a classroom.
- There is no option to create a counterfactual or control group.
- There is considerable heterogeneity in the population receiving the intervention, the wider context of the intervention or the intervention itself. Such heterogeneity would make it impossible to estimate the average treatment effect using a traditional counterfactual evaluation, as different sub-groups will be too small for statistical analysis (White and Phillips 2012).
- There is substantial complexity in the programme being evaluated, meaning that an evaluation designed to answer the question ‘does the programme cause outcome X’ may make little sense, whereas an evaluation design that recognises that the programme is just one ingredient in a ‘causal cake’ may make more sense.
In these situations, a theory-based evaluation still offers the possibility of making causal statements about the relationship between an intervention and an outcome.
Important limitations of theory-based methods include:
- Many of these methods do not allow evaluators to quantify the size of an impact. This can also reduce options for subsequent economic evaluation.
- These methods all involve detailed information gathering at the level of the case; in some theory-based evaluations, gathering in-depth qualitative data from one or more cases could be just as time-consuming and resource-intensive as data collection in a traditional, counterfactual impact evaluation.
- All evaluation requires that evaluators have the necessary skills in evaluation design, data collection, analysis and report writing. However, in a theory-based evaluation, the evaluator additionally needs a deeper knowledge of the programme and the context within which it is being implemented than might typically be required in a traditional, counterfactual impact evaluation.
How do theory-based impact evaluations work?
How do theory-based impact evaluations work?
Theory-based evaluations draw on different understandings of causation from ‘traditional’ counterfactual impact evaluations.
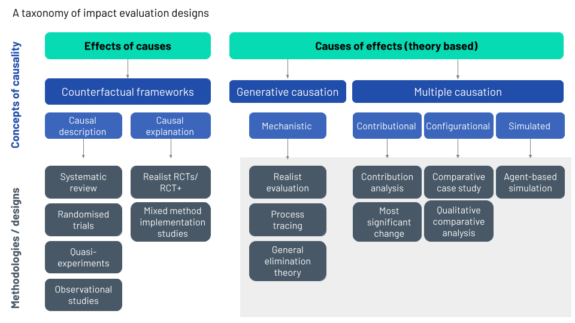
All the methodologies that we describe have certain elements in common:
- Mid-level theory: All the approaches to impact evaluation associated with uncovering ‘causes of effects’ involve specifying a mid-level theory or a theory of change together with alternative causal hypotheses. Causation is then established beyond reasonable doubt by collecting evidence to validate, invalidate or revise hypothesised explanations (White and Phillips 2012). Mid-level, or middle range, theory is a sociological concept that attempts to combine high-level abstract concepts with concrete empirical examples. As such, it makes hypothesis development possible by bringing data and evidence together with theoretical constructs to help make sense of the subject under investigation. Mid-level theories can also support a focus on causal mechanisms operating at a more general level than the context of specific individual interventions. As a result, they encourage the identification of patterns and ‘regularities’ across a range of interventions or contexts. This process can support the development of generalisable conclusions and, therefore, the transfer of hypotheses between related interventions or contexts.
- Cases: Key to all theory-based approaches is the concept of the ‘case’. However, they are not ‘case studies’. Case-based methodologies are varied but Befani and Stedman-Bryce (2017) suggest that case-based methods can be broadly typologised as either between-case comparisons (for example, qualitative comparative analysis) or within-case analysis (for example, process tracing).
- Mixed method: Generally, quantitative and qualitative data are used, with no sharp distinction made between quantitative and qualitative methods.
- Complexity: In counterfactual approaches, the two concepts of bias and precision are central to managing uncertainty. Sources of uncertainty are controlled through both research design (randomisation where possible and sample size/statistical power) and precision (e.g. methods of statistical inference, computation of confidence intervals, p-values, effect sizes and/or Bayes factors). In contrast, theory-based approaches are case-based, and the multifaceted exploration of complex issues in real-life settings allows these approaches to account for uncertainty through invoking concepts centred on ideas of complexity.
- Generative and multiple causation: Within approaches to theory-based evaluation, Stern and colleagues (2012) make a broad distinction between approaches based on generative causation and those based on multiple causation. Multiple causation depends on combinations of causes that lead to an effect, whereas generative causation understands causation as the transformative potential of a phenomenon and is closely associated with identifying mechanisms that explain effects (Pawson and Tilley 1994).
Getting started with a theory-based evaluation
Getting started with a theory-based evaluation
Before starting any impact evaluation, consider the key issues concerning resources and constraints and only start an evaluation if these questions can be answered satisfactorily.
- Does the institution have sufficient resources (e.g. direct or in-kind funding) to conduct an evaluation? Issues to consider may include the burden associated with data collection for both students and practitioners, ethics, likely response rates, level of engagement and the possible impact that data collection may have on the programme and student outcomes.
- When is the evaluation report needed and can the evaluation realistically deliver within this timescale? In the context of higher education, the academic calendar (i.e. holidays) should be considered alongside the nature of the data collection required and the timeframe of the evaluation.
- Do the institution’s staff have the necessary expertise (i.e. knowledge and skills) and capacity (i.e. time and resources)?
Theory-based evaluation designs should be considered when one or more of the following are true:
- There is one case or a small number of cases. (A case could be an organisation as well as a person).
- There is no option to create a counterfactual or control group.
- There is considerable heterogeneity in the population receiving the intervention, the wider context of the intervention or the intervention itself. Such heterogeneity would make it impossible to estimate the average treatment effect using a traditional counterfactual evaluation as the different sub-groups will be too small for statistical analysis (White and Phillips 2012).
- There is substantial complexity in the programme being evaluated, meaning that an evaluation designed to answer the question ‘does the programme cause outcome X’ may make little sense, whereas an evaluation design that recognises that the programme being evaluated is just one ingredient in a ‘causal cake’ may make more sense.
Befani (2020) has developed a tool to choose appropriate impact evaluation methodologies. It covers a wide range of theory-based impact methods as well as ‘traditional’ counterfactual evaluation designs. We recommend that you familiarise yourself with this tool and use it as an aid to decide which evaluation methodology to use.
For all the methodologies described here, an important starting point is to develop a detailed theory of change.
Theory of change
Theory of change
Overview
All theory-based evaluations begin with a detailed theory of change. We recommend using TASO’s Enhanced Theory of Change template.
A useful theory of change must set out clearly the causal mechanisms by which the intervention is expected to achieve its outcomes (HM Treasury 2020). The Magenta Book (HM Treasury 2020) details how more sophisticated theory of change exercises produce a detailed and rigorous assessment of the intervention and its underlying assumptions, including the precise causal mechanisms that lead from one step to the next, alternative mechanisms to the same outcomes, the assumptions behind each causal step, the evidence that supports these assumptions, and how different contextual, behavioural and organisational factors may affect how, or whether, outcomes occur.
What is involved?
There is no set method for developing a theory of change. The process often starts with articulating the desired (long-term) change that a programme or intervention intends to achieve, based on a number of assumptions that hypothesise, project or calculate how change can be enabled. The following questions, based closely on the Early Intervention Foundation’s 10 Steps for Evaluation Success, can be used to structure the process of building a theory of change:
- What is the intervention’s primary intended outcome?
- Why is the primary outcome important and what short and long-term outcomes map to it?
- Who is the intervention for?
- Why is the intervention necessary?
- Why will the intervention add value?
- What outputs are needed to deliver the short-term outcomes?
- What will the intervention do?
- What inputs are required?
To be a useful starting point for a theory-based evaluation, the theory of change must set out clearly the causal mechanisms by which the intervention is expected to achieve its outcomes. An understanding of the causal mechanisms will develop from both engagement with key informants and an understanding of the scientific evidence base.
The development of a theory of change is fundamentally participatory. Evaluators should include a variety of stakeholders and, therefore, perceptions. The process of developing a theory of change should be based on a range of rigorous evidence, including local knowledge and experience, past programming material and social science theory. It is common to use workshops as part of the process, but document reviews, evidence reviews and one-to-one interviews with key informants are also likely to feature.
– Case study: Theory of change (PDF)
– Briefing: Theory of change (PDF)
Useful resources
Many organisations have produced guidance on the theory of change.
TASO has produced guidance on developing a theory of change as part of its wider evaluation guidance. This is supported by videos discussing theory of change and how to run a theory of change workshop.
Many other organisations have also produced guides. A few of these include:
Asmussen, K., Brims, L. and McBride, T. (2019) 10 steps for evaluation success, London: Early Intervention Foundation. See pp. 15–26.
Noble, J. (2019) Theory of change in ten steps, London: New Philanthropy Capital.
Rogers, P. (2014). Theory of Change, Methodological Briefs: Impact Evaluation 2, UNICEF Office of Research, Florence.
A helpful worked example of how to build a Theory of Change produced by ActKnowledge and the Aspen Institute Roundtable on Community Change is available on Centre for Theory of Change.
Theory-based evaluation methods
Find out more about theory-based evaluation methods, from agent-based modelling to realist evaluation.